In manufacturing, a dark factory is a facility that operates with no human presence. Lights off, machines running. The term comes from the simple fact that no one is there to need the lights.
A dark software factory is the same idea applied to code. An autonomous system that produces software with minimal human intervention. You define what to build. The factory handles how: decomposing work, writing code, testing, reviewing, iterating. It runs for hours or days. You come back to a working application.
AI labs are already building these internally. On March 24, Anthropic engineer Prithvi Rajasekaran published a post on harness design for long-running AI coding sessions. He describes a multi-agent architecture (planner, generator, evaluator) that builds complete applications autonomously. As a demonstration, they built a browser-based Digital Audio Workstation.
I read the post and recognized the architecture. The approach is structurally close to what I have been building in the open with compound-agent, the system I described in a previous post. Same separation between planning, building, and evaluating. Same insight that generators should not judge their own output. Same conclusion that context resets beat context compaction.
So I ran the obvious experiment. Same brief: a browser-based DAW. Same class of model, but leveraging multiple providers. I wanted to see what an open-source harness produces against a frontier lab's internal tooling, on a benchmark they chose. The result is live here (desktop only — a DAW is not a mobile product).
What Anthropic Built
Their DAW ran for 3 hours 50 minutes on Claude Opus 4.6. Total cost: $124.70 across three build-and-review rounds.
Their evaluator found gaps in feature completeness and interactive depth through the QA process. They note the result "fell short of professional music production standards." The harness itself is not published.
What compound-agent Built
The system decomposed the project into 18 tasks ordered by dependency. Each went through the full cycle: specification, planning, test-driven implementation, multi-agent review, lesson extraction.
The result is a working DAW with functional internals:
- Audio engine. Subtractive polyphonic synth, sampler, and DSP running in AudioWorklet processors for clean threading.
- Sequencing and UI. Canvas-based piano roll, arrangement view with clip dragging and grid snapping, automation lanes with breakpoint editing across multiple curve types.
- Mixing and persistence. Per-channel mixer with six insert effects, Web MIDI support, IndexedDB/OPFS auto-saving with crash recovery, and offline WAV bounce.
Not display-only features. Real DSP, real state management, real persistence.
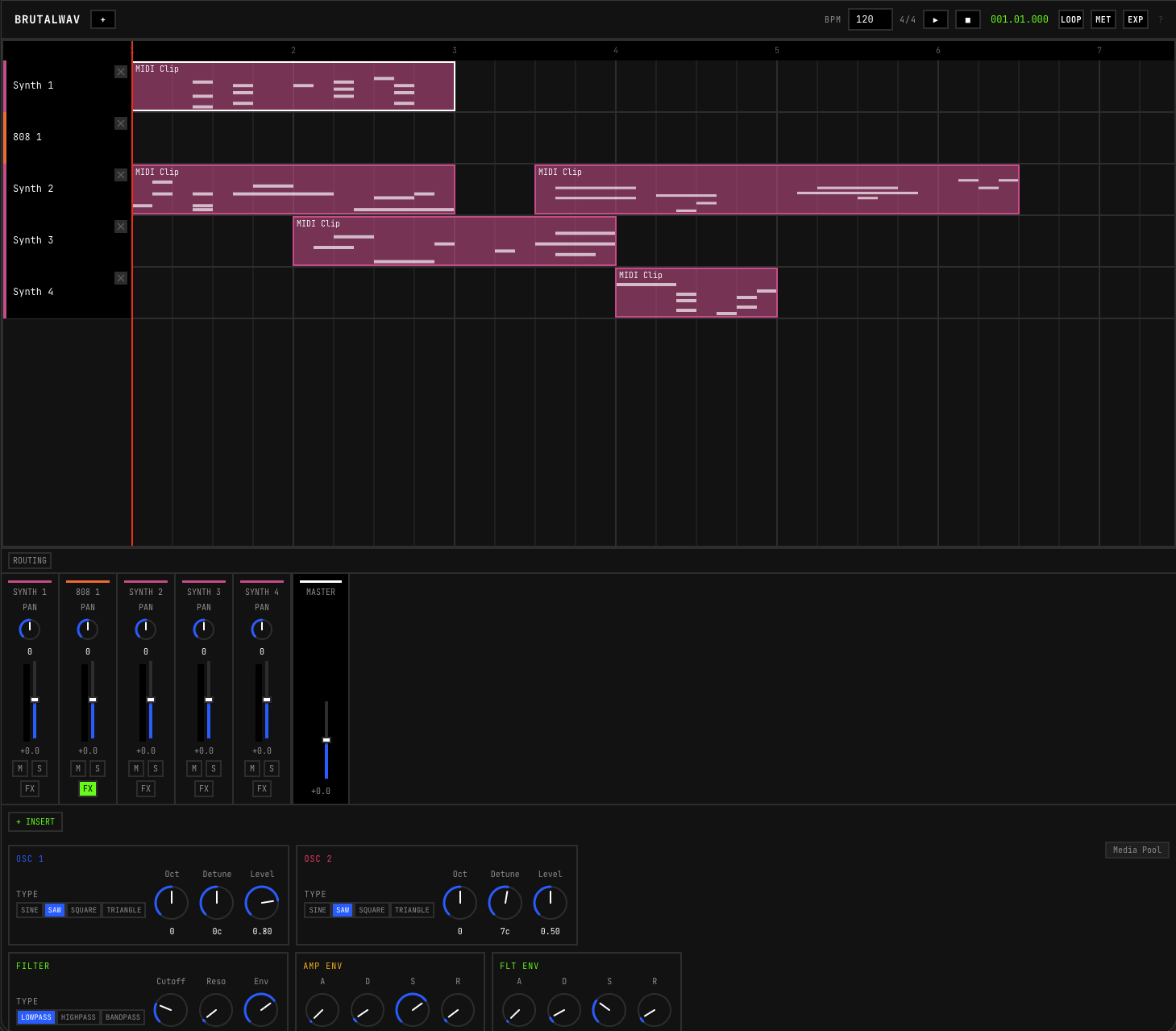 The arrangement view with per-channel mixer, faders, and insert effects.
The arrangement view with per-channel mixer, faders, and insert effects.
The build took roughly 20 hours of autonomous work across multiple sessions on a $200/month Claude Max subscription. I set up the environment with Claude, then worked with it to produce and refine the initial specification through a few clarification questions. Once the autonomous loop began, I was away from my computer. The agents wrote tests, built features, ran verification, and extracted lessons between sessions. I only came back at the end to test the app and review it like a beta tester.
The Comparison
Both approaches rest on the same primitive but differ in execution.
Where they converge:
- Separating generation from evaluation. Both systems use distinct agents for building and reviewing. Rajasekaran found that agents confidently praise their own mediocre work, especially on subjective dimensions. Separating the roles fixes this.
- Planner as a first pass. Both use a dedicated planning step to expand a brief into a structured specification before code is written.
- Context resets over compaction. Both found that fresh context produces better results than compressed conversations. Anthropic documented a specific failure mode: models would prematurely wrap up work as context limits approached. Clean resets eliminate this. The consequence is that context and task state must live in the codebase, not in the agent session.
Where compound-agent extends the approach:
- Persistent memory across sessions. Anthropic's harness is stateless. Every run starts from zero.
compound-agentstores lessons, solutions, and patterns in a searchable memory layer (JSONL backed by SQLite with semantic embeddings). Mistakes are captured once and not repeated. - Multi-model review. Their evaluator is a single agent using Playwright.
compound-agentruns multiple specialized reviewers in parallel across different models and providers. Every model has blind spots. They are not the same blind spots. A gap one model misses gets caught by another. - Cost model. Their build cost $124.70 in API credits. Mine ran on a flat monthly subscription. These are different pricing models and not directly comparable. But the implication matters: API pricing gates long autonomous runs behind per-token economics. A flat subscription makes them accessible to individual developers.
Anthropic's build was faster: 3 hours 50 minutes versus roughly 20 hours. But wall-clock time is less relevant here because this was autonomous work. The agents ran unattended across multiple sessions while I lived my life. The relevant metric is human time invested.
What I Learned
Specifications are not optional. Most interesting projects fall between clearly scoped tickets and vibes. For those, you need a structured document: scope, constraints, acceptance criteria. compound-agent is designed for this. Its initialization phase lets you tag-team with Claude to define precise specs before the autonomous loop begins. That upfront investment is what makes multi-session orchestration produce coherent products.
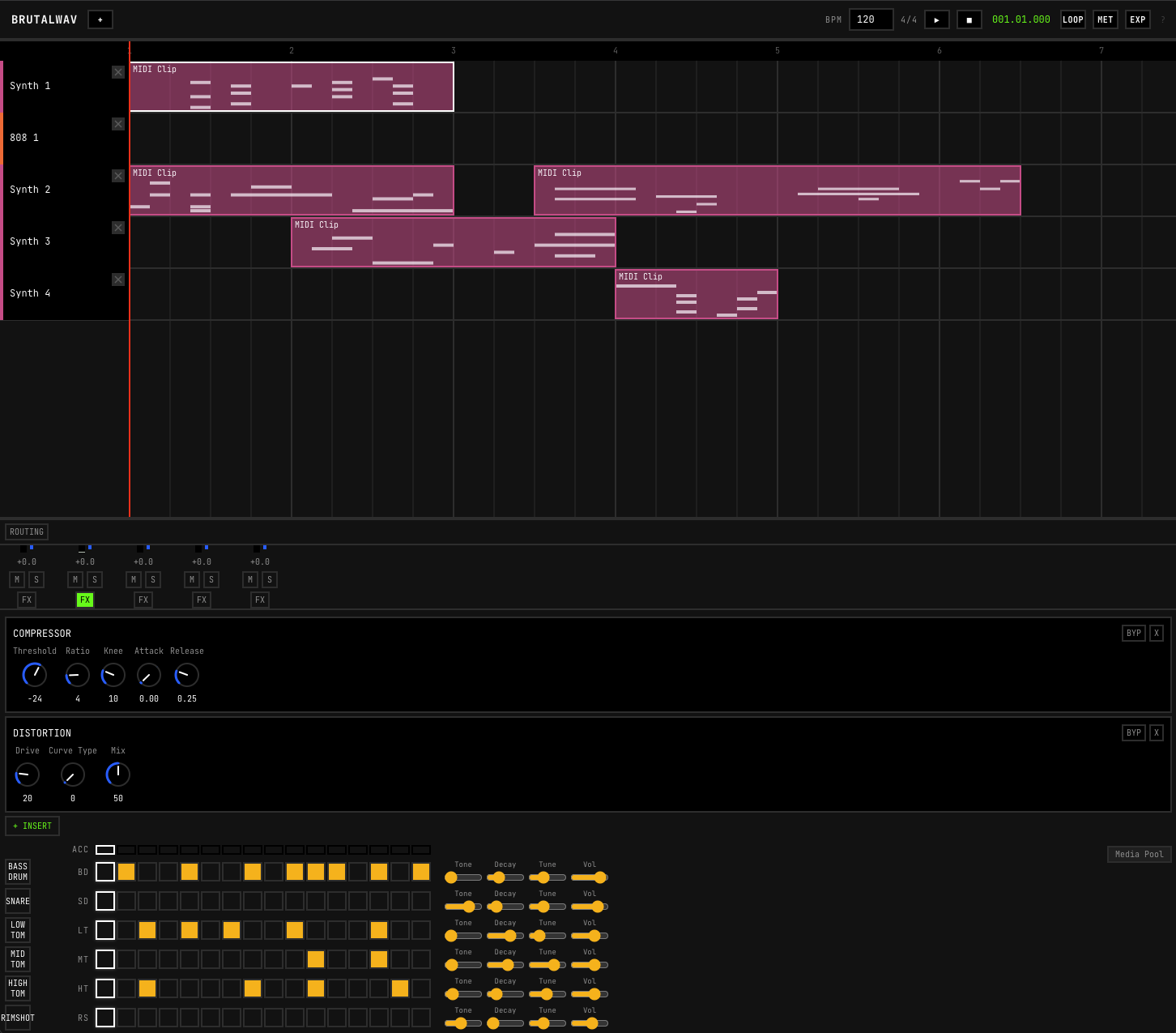 The step sequencer for drum pattern programming.
The step sequencer for drum pattern programming.
AI makes different errors, not fewer. After 20 hours of autonomous work, the DAW was architecturally complete. But there was no "add track" button. The system handled tracks perfectly once they existed. The most basic user action was missing. A human might struggle with the AudioWorklet threading model but would never forget the button. This is not a failure of intelligence. It is a different kind of intelligence with different blind spots. Every human project needs a review round too. I have never seen a perfect first delivery from a human team either.
The Factory is Open
Rajasekaran makes a point worth engaging with: "every component in a harness encodes an assumption about what the model can't do on its own." As models improve, harness complexity might decrease. The goal is light scaffolding, not heavy machinery.
What stays durable is the memory layer and the multi-agent review structure. Models will get better at coding. But current models do not reliably remember what happened three sessions ago or catch their own blind spots.
The other piece that matters is expert knowledge accessible to agents. Deep documentation on architecture, standards, patterns. Not baked into the harness, but queryable on demand. The harness orchestrates. The documentation teaches. This separation keeps things simple.
The models are already accessible through subscriptions and APIs. The missing piece is the harness: orchestration, memory, feedback loops. This benchmark suggests that an individual developer can assemble those pieces today and build their own dark software factory.
Notes
The harness code and documentation live at Nathandela/compound-agent. Install with pnpm install compound-agent@latest then npx ca setup (beads is also required). The DAW source code is at Nathandela/long-running-harness.
The DAW is live at nathan-delacretaz.com/daw. Create a synth track. Draw notes in the piano roll. Create a drum machine track. Tap the pads, it loops. Route both through the mixer, add some reverb. Hit play. That is 20 hours of autonomous work you are listening to.